Core Concepts
Pipelines
A pipeline is a sequence of steps that together create an automated workflow.
Steps are executed in series or in parallel, and data can be passed from one step to subsequent steps. Pipelines can be built using the visual pipeline builder in Sophos Factory, which includes a side-by-side text editor for the underlying YAML definition.
A set of inputs (called variables) and outputs can be defined for each pipeline. Variables can be provided when executing a pipeline, either via API or through rich, dynamic forms in Sophos Factory.
Reusable Component Pipelines
A whole pipeline can be included as a step in other pipelines. These reusable component pipelines enable powerful modular workflows.
Revisions
Pipelines have revisions so they can be version-controlled. You can run any revision of a pipeline at any time. Visit your pipeline’s page to see all its revisions and choose one to run.
Step Modules
The action performed at each step of a pipeline is defined by the step module type. Modules eliminate the heavy lifting of running automation tools by providing a powerful low-code interface, seamless authentication using credentials, and automatic installation of any necessary tools and dependencues during the pipeline run.
A wide variety of built-in step modules are available, including steps for popular scripting languages, configuration management tools, infrastructure automation tools, and security automation tools.
A powerful feature of Sophos Factory is the ability to include whole pipelines as steps in other pipelines. In addition to the built-in step modules, you can build your own reusable component pipelines with structured inputs and outputs that can be shared with others.
Variables
Variables are structured data values that pipelines use at runtime.
Each variable is a key-value pair, stored in the vars array. Variable keys may not contain dashes (-).
To set a value for a variable in the application, input the value in the form field text box. To unset the value, clear the form field and submit the form.
If using the API, pass the value in the request body:
variables: {
variable_key_name: 'My Variable Value'
}
To unset a value, provide either an empty string or null in the request body:
variables: {
variable_key_name: '',
another_variable: null
}
To access a variable from an expression, assuming the variable key is hostname, use vars.hostname.
Variables have scopes, which are:
- Project variables, available to all pipelines in the project.
- Pipeline variables, available at the pipeline scope.
- Job variables, available at the job scope.
- Variables set with the Set Variables step module.
Variables lower in this list will override those higher up if they have the same key. For example, pipeline variables can be overridden at runtime. This can be done by setting variables on a job, or setting the run inputs (for a top-level pipeline), or by the step properties (for a component pipeline).
Variable Configuration
When adding a Project or Pipeline variable, you have a few options.
- Variable Type: allows you to choose from a set of variable types, which are:
- String
- Secure String (contents will be masked in run output)
- String Array
- Number
- Number Array
- Boolean
- Credential (see Credential Types for more info)
- Code
- Friendly Name: a human-readable name for your variable, such as “Last Name”.
- Key: the name you’ll use to refer to the variable in an expression, for example, input
last_nameto refer to this variable withvars.last_name. Variable keys cannot contain the dash-character (vars.host-namewould not be a valid variable key). - Description: lets you write a short note to remind yourself what this variable is for and how it’s used.
- Required: mark this variable as required if you don’t want a Pipeline to run without it.
- Visible: visible variables can have their values changed by someone on the Job page, or at runtime.
- Allowed Values: lets you restrict the values that can be chosen for this variable.
- Value: allows you to set an initial value for this variable.
- Use as default value: can be set to true (turned on) if you want the above value to be filled in when someone leaves this variable empty.
Debugging Variables
For debugging variables, it is useful to use a Debug Message step module. To show all the variables and values, use vars | dump(2) in the Message field.
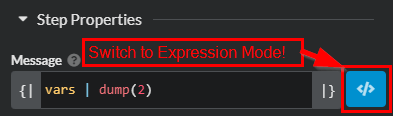
Expression Mode
Some fields need to be toggled from Inline Mode to Expression Mode in order to evaluate expressions.Show a single variable and value using "Hostname: " + vars.hostname in the Message field.

Expressions
Expressions allow manipulation of data during pipeline execution.
Using Sophos Factory’s powerful expression evaluation engine, data can be manipulated using expressions that evaluate just before a step executes.
Built-in functions and contextual variables allow you to retrieve and transform data from one pipeline step to the next.
To learn how to write expressions, see the Expression Reference.
Credentials
Credentials are reusable authentication details. They can be passed into step modules, eliminating the complexity of authenticating with the underlying tools.
Credentials are treated as first-class variable types. This allows you to define a credential as a dynamic input to a pipeline. Many common credential types are supported, including SSH keys, passwords, and API tokens.
For more details about credentials and how to use them, see Credential Types.
Jobs
A job defines how and when a pipeline executes, including its trigger type, predefined input variables, and runtime behavior. Jobs are useful for creating a reusable set of of pipeline inputs. Jobs can also be triggered on a recurring schedule. Pipelines can also be run directly without a job.
Runs
Running a pipeline or job creates an individual run. A run stores detailed run output, or a log, for each executed step. Runs are automatically deleted after the retention period of your subscription plan.
Projects
Pipelines, jobs, and other application objects are organized in projects. Projects are the primary scope for access control, so you can control who in your organization can see and modify data by assigning users and groups to projects.
Organizations
Organizations are shared accounts that allow collaboration within a real-world organization. All users are associated with a primary organization, and organization administrators can control which projects users have access to.
Runners
Runners are machines that execute pipelines. Sophos Factory provides secure, cloud-hosted runners out-of-the-box that allow you to get started quickly.
You can also host runners in your own Linux environment with a self-hosted runner. Learn more about runners here.