Pipeline Best Practices
Users often ask about best practices for building pipelines. The following represent some best practices that come from Sophos' experience building pipelines for internal use and for use by our customers and partners. These guidelines are intended to provide a starting point for customers and partners, to inspire new ideas and to start discussions on how they might be improved. It is almost certain that this list can and will be improved and/or expanded over time.
There are two categories of recommendations here. The first consists of basic guidelines for building pipelines. The second provides guidelines on pipeline architecture around specific technical roles.
Basic Guidelines
There are some basic guidelines that apply to all pipelines. I will cover those first. Later, we will talk about different types of pipelines and how the basic guidelines should be applied for each type.
Managing pipeline complexity
Pipelines should be kept as simple as possible. Ideally, this means a pipeline should have no more than a dozen or so steps. The point is to make the pipeline understandable. Keeping the number of pipeline steps to a minimum, makes the flow of the pipeline clearer when viewed in the graphical pipeline builder.
There are times when a pipeline under active development starts to look like a bowl of spaghetti and meatballs. This usually means that it is time to consider simplifying the pipeline. One of the best ways to do this is to extract several related steps, create another pipeline and then including the new pipeline as a step in the original pipeline. There are many times when using two simpler pipelines is better than trying to cram everything into a single, more complex pipeline.
Limit pipeline depth
Including pipelines as steps in other pipelines is definitely a best practice. However, it is easy to go overboard. If you create too many levels of included pipelines, it starts to add complexity – something we want to avoid. We call this pipeline depth – the number of levels of included pipelines in your solution. The maximum recommended pipeline depth is two. That means that a top level pipeline can include one or more component pipelines. Each component pipeline can include one or more library pipelines. Ideally, library pipelines should not include any other pipeline as steps. This is illustrated in the diagram below.
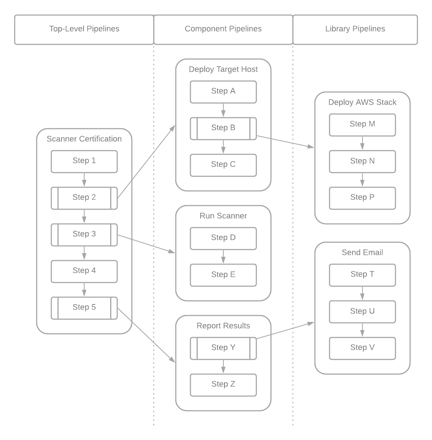
The categories names used here – “top-level pipeline”, “component pipeline” and “library pipeline” – were chosen intentionally. We will revisit these concepts shortly.
Using pipeline variables effectively
Visible pipeline variables are defined in the Variables dialog in the pipeline builder and are very important. These variables are the inputs for the pipeline. Visible pipeline variables appear whenever the pipeline is used or referenced. They appear in the run dialog when the pipeline is executed. They also appear in the job definition dialog when a job is created that uses the pipeline. Finally, they appear in the step properties dialog whenever the pipeline is included in another pipeline.
Having too many pipeline variables seems like a “code smell”. The question is, “How many are too many?” Generally speaking, a pipeline should have no more than six to eight pipeline variables. This is especially true when the pipeline will require direct user input. A pipeline that is intended to be used as an included pipeline can get away with a few more visible variables, if required. However, any pipeline that is approaching a dozen or more pipeline variables should be extremely rare, maybe nonexistent.
Each visible pipeline variables should have a concise description. The description will be displayed in both the run dialog and the job definition dialog, but not in the step properties dialog. Ideally, the description should be one line or less. In no case should it exceed two or three lines. If a pipeline variable requires a more in-depth explanation, it should be move to an external document such as a User’s Guide.
Credentials as variables
Many pipelines contain steps which require some type of credential. Sophos Factory includes a secure credential store. The credentials used by pipelines and their steps should be created in the credential store and then selected when needed.
When adding a step that requires a credential, do not enter an actual credential from the credential store directly in the step property. Instead, add a pipeline variable of the same credential type. Give it a meaningful name like vars.credential or vars.awsCredential. Then, use the variable in the property of the pipeline step. When credential are used defined and used this way, a user or job running the pipeline can prompt the user for the credential to be used. It also allows an including pipeline to specify the credential to be used through the corresponding step property.
Usually it’s recommended to leave credential variable values empty in the pipeline itself, instead providing a value in a job or when running the pipeline. This helps decouple the pipeline from particular credentials, which could eventually be deleted or renamed. If you plan to share or clone a pipeline to another project, note that credential variable values will be automatically cleared from the pipeline variables. Since credentials are scoped to project, this prevents the pipeline from accidentally having the wrong credential configured in the destination project after cloning.
Unique identifiers and naming conventions
Using a consistent naming convention for objects is important in any technical context. At the very least, this consistency helps to avoid ambiguities about proper capitalization for multi-word identifiers such as deployScanTarget. It can also help to identify the scope of the identifier. In fact, it can prevent variable scope conflicts.
We use and recommend camelCase for all of our object identifiers. However, other valid choices include PascalCase, lowercase and snake_case. There are likely other naming conventions that would work. The point is to choose one standard and stick with it. You’ll be glad you did.
In Sophos Factory, there are several types of objects that require a unique identifier. For project variables, pipeline variables, pipeline outputs, and variables defined in a “Set Variables” step, the unique identifier is the key property. For project credentials and pipeline steps, the unique identifier is the id property.
The value of each object’s identifier must be unique within the object’s type and scope. This means that the key of a project variable must be unique within the project variables; the ID of a project credential, within the project credentials; the ID of a pipeline step, within the pipeline’s steps; the key of a pipeline variable, within the pipeline variables; and the key of a variable defined in a “Set Variables” steps, within the “Set Variables” step.
Variable keys and precedence
Variables can be defined three different ways – as a project variable, as a pipeline variable, or by the “Set Variables” step. All three types of variables are referenced in the same way using vars.<key>. It is possible to define a project variable, a pipeline variable and a step variable all with the same key – for example, myVariable. When an expression includes a reference to vars.myVariable, which variable’s value is used in the expression?
The documentation topic, Accessing variables from steps, states that the value of the step variable would be used. The logic is more or less like the following.
- If
vars.myVariableis defined in a “Set Variables” step, use its value. Otherwise… - If
vars.myVariableis defined as a pipeline variable, use its value. Otherwise… - If
vars.myVariableis defined as a project variable, use its value.
While this process is logical, it can certainly lead to confusion and wasted time when trying to debug unexpected behavior in a pipeline.
The simple solution is to avoid using duplicate variable keys at the project, pipeline and step levels. Instead, use a naming convention that distinguishes the variables in each scope. For example, you could prefix project variable keys with prj and pipeline variable keys with p. Using that approach, vars.prjMyVariable would be a project variable, vars.pMyVariable would be a pipeline variable and vars.myVariable would be a step variable. Now there is no confusion between the three. The idea is to make it less likely that the same variable name would be defined at multiple levels.
Granted, in some cases, this might be overkill. Project variables are – or should be – used infrequently in most solutions. There is usually a better way to get to a value than using a project variable. Project credentials are selected by users who only see the Display Name. The credential ID should be stored in a pipeline variable and expressions will reference the pipeline variable, not the credential ID. Pipeline variables and variables defined in a “Set Variables” step are all within the scope of the pipeline and any name conflicts should be relatively easy to find.
About generated step IDs
For pipeline steps, the graphical builder gives each step a unique ID when the step module or included pipeline is dragged into the pipeline builder. This default ID is a short, lower-case code that identifies the type of step followed by a unique number – for example, vars1 for the first “Set Variable” step. While these default step IDs are always unique, they aren’t very meaningful. It is recommended that each step ID be set to a more meaningful value. For example, instead of the default, vars1, name your “Set Variables” step step something like setDefaultValues or setTokenValue. At the same time, each step’s display name should be updated to something meaningful such as “Set Default Values” or “Set API Token”. Remember that the display name of each step appears in the run history when the pipeline is executed. For debugging purposes, do yourself a favor and avoid cryptic names.
Pipeline Categories
As we have worked with customers to build solutions on Sophos Factory, we have seen pipelines fall into three general categories. These categories - top-level pipeline, component pipeline and library pipeline – are primarily based upon the way that each pipeline is used in the solution. This list is not meant to be definitive. There are likely other useful categories of pipelines that I have not mentioned here and some pipelines might fall into more than one of these categories. In the end, these categories are offered as an aid to get us thinking about how we use each pipeline we build.
Top-level pipelines
Top-level pipelines are those that will be executed by end users either directly or through a job definition. Typically, these pipelines implement business logic that include several technical components. The business logic can be complex and might require coordination of several tools and technologies, may span multiple business domains and could involve trading partners.
Here are some examples of top-level pipelines:
- Integration of ticketing systems across multiple trading partners. This process might have several top-level pipelines.
- Network Automation of device firmware upgrades across multiple device vendors and types. This process might have a top-level pipeline that initiates one or more included pipelines for each device depending on its manufacturer and model. It could use library pipelines to send notifications of the initiation and completion status of each upgrade.
- Certification of a vendor’s security scanning tool against industry standards. This process could require deployment of a known image in a public cloud, scanning of the image with the vendor’s tool before and after arbitrary remediation of the image, and collating the vendor tool’s results with a set of known results for evaluation and, finally providing the results to both the vendor and the standards organization.
Guidelines for top-level pipelines
Despite the underlying complexity, a top-level pipeline should be easily understandable by three audiences: the users who execute the job, other non-technical stakeholders, and the engineer(s) responsible for maintaining the pipeline. Consequently, the most important guideline for a top-level pipeline is avoiding and/or hiding complexity.
Firstly, this means keeping the number of pipeline variables to a minimum – preferably no more than six and only those that are absolutely required. Ensure that the values required for each variable are well-documented and readily available to the pipeline user. The meaning and value of each pipeline variable should be crystal clear.
When credentials are required to execute the pipeline, use appropriately-typed credential pipeline variables. Also, be sure to provide the user with instructions for creating an appropriate credential in the credential store that they can use hen executing the job or pipeline.
Secondly, this means including component pipelines as steps to minimize the total number of steps – preferably no more than a dozen. Each step in the pipeline should represent a phase of the business logic. The steps should be arranged so that they clearly illustrate the flow of information through the pipeline. It is likely that many of the steps in a top-level pipeline will be included pipelines (see component pipelines below). This approach of including pipelines as steps must be balanced with the guideline for pipeline include depth.
Component pipelines
A component pipeline implements a self-contained process (business or technical). They are designed to be included as a step in a top-level pipeline. For example, a component pipeline might provide integration with a cloud platform, security scanning tool or business application; implement a selected subset of business logic for specific business domain; or interact with a business or technical trading partner.
Here are some examples of component pipelines.
- Scanning a host for vulnerabilities with a tool – for example, CIS-CAT or OpenSCAP – and returning the results as a pipeline output. This might include a (library) pipeline step that ensures the tool is installed and properly configured.
- Creating one or more cloud resources from source code – for example, an AWS CloudFormation stack using a CFT or Azure Resources using an ARM template – and returning the IP Address and DNS name for later connectivity.
- Scanning source code and/or third-party libraries for vulnerabilities using a third party tool such as Checkmarx SAST or RunSafe Alkemist.
Guidelines for component pipelines
Because component pipelines are usually included in a top-level pipeline, their implementation details are not as visible to non-technical users. However, complexity is still a concern for the engineer(s) maintaining the pipeline. So, a component pipeline may contain more steps than a top-level pipeline, but still not too many.
Some of the steps in a component pipeline could be included pipelines (see library pipelines below). This will help keep complexity to a minimum.
A component pipeline will likely have outputs defined on the Variables dialog. Outputs can make it easier to use the results of a component pipeline when included in top-level pipelines.
Library pipelines
Library pipelines tend to be very simple and perform a single low-level action. They are designed to be used as included pipelines in other pipelines. Typically, a library pipeline is included in one or more component pipelines. Occasionally, a library pipeline might be included in a top-level pipeline.
Here are some examples of simple pipelines:
- Post a notification message to a Slack or Teams channel
- Clone a Git repository
- Upload files to an AWS S3 Bucket
- Install and configure a CLI-based security tool
Guidelines for library pipelines
Typically, a library pipeline has only a few pipeline variables as inputs. It will probably have some outputs defined. These pipelines implement atomic, re-usable logic. Consequently, they usually have only a few steps, none of which is an included pipeline. They are (or should be) easily tested without any dependence on other pipelines.